Benchmarking some Latin hypercube sampling libraries
As of February 2025, the experiment-design library outperforms all other tested |LHS| implementations,
achieving the lowest correlation error and best space-filling properties.
Key advantages of experiment-design:
Lowest correlation error across all dimensions and sample sizes
Best space-filling properties, with higher minimum pairwise distance
Only library with native support for correlated variables, non-uniform distributions, and LHS extension
Results
Correlation error
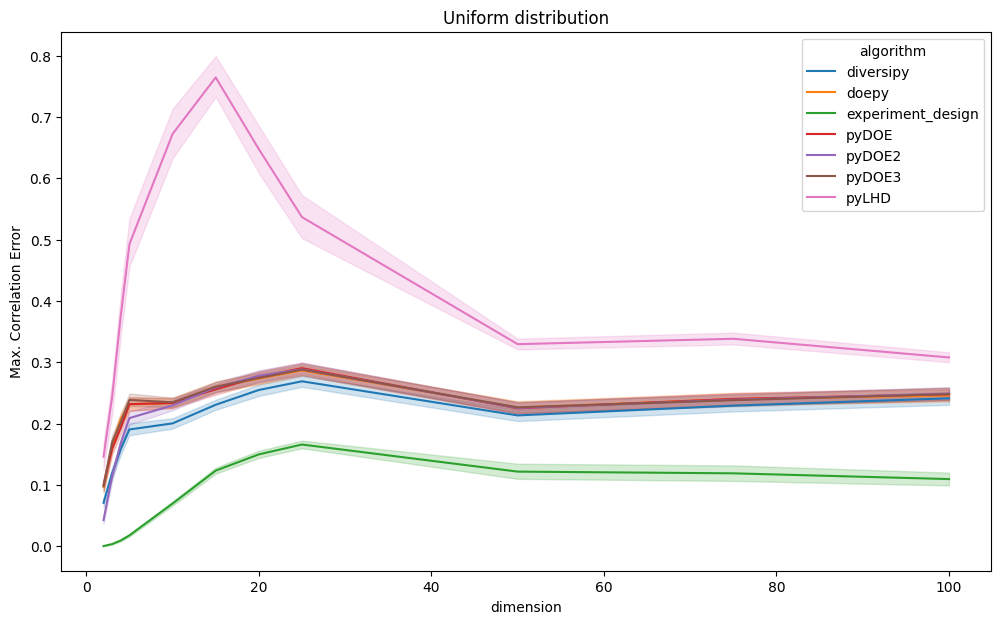
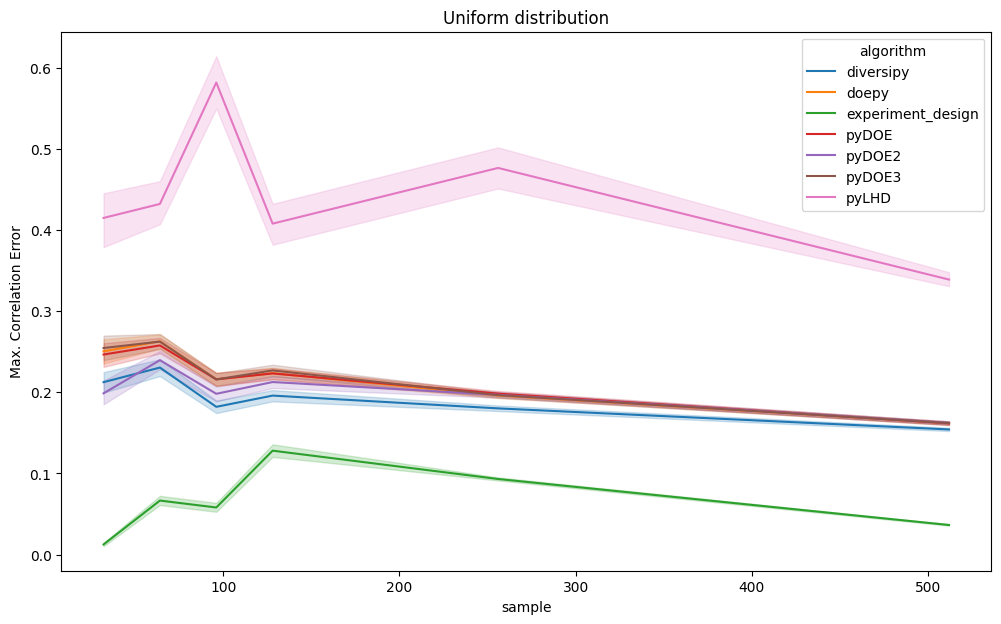
The plots below show mean and maximum correlation error results, grouped by dimension and sample size. Since these are error metrics, lower values indicate better performance. Lines represent the average values of the metrics, whereas the areas represent the 95% confidence intervals.
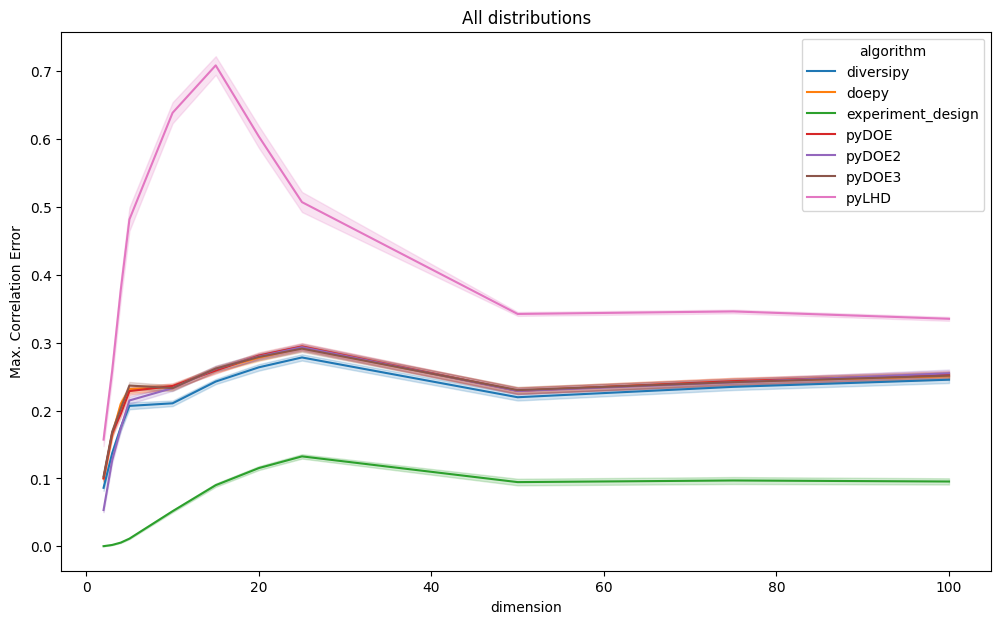
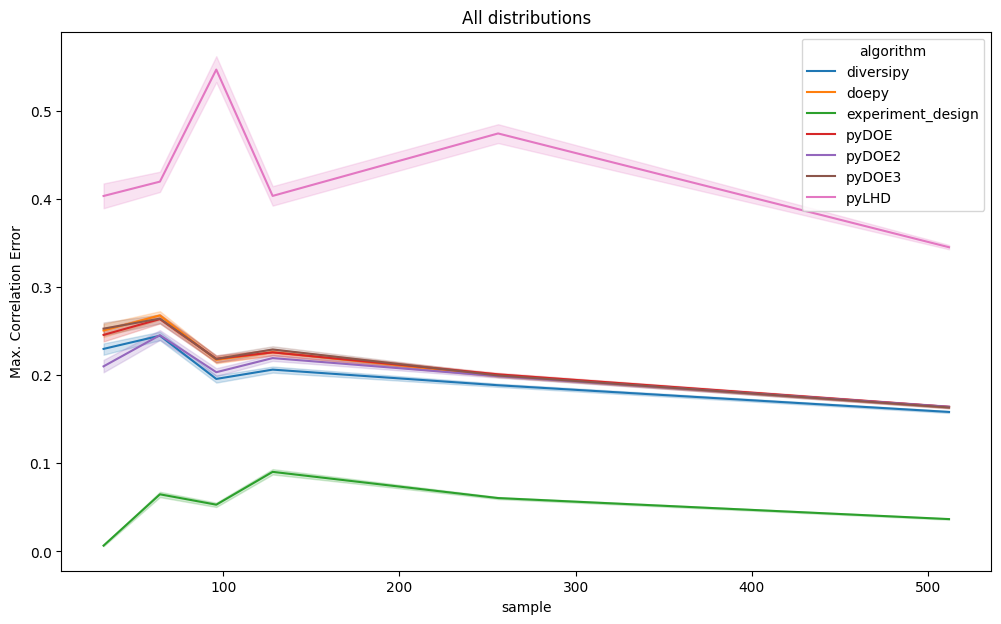
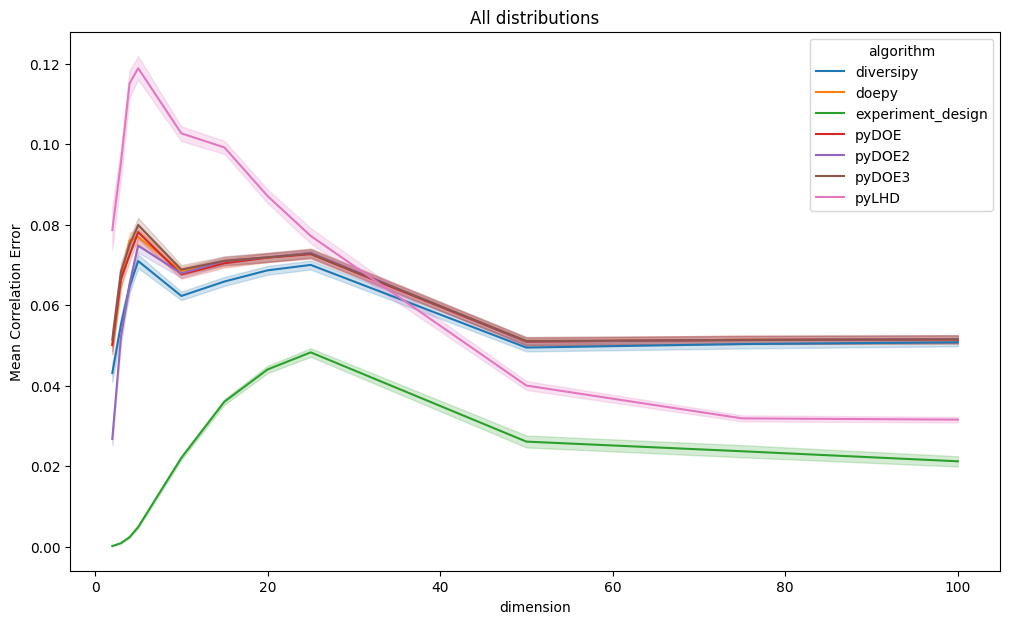
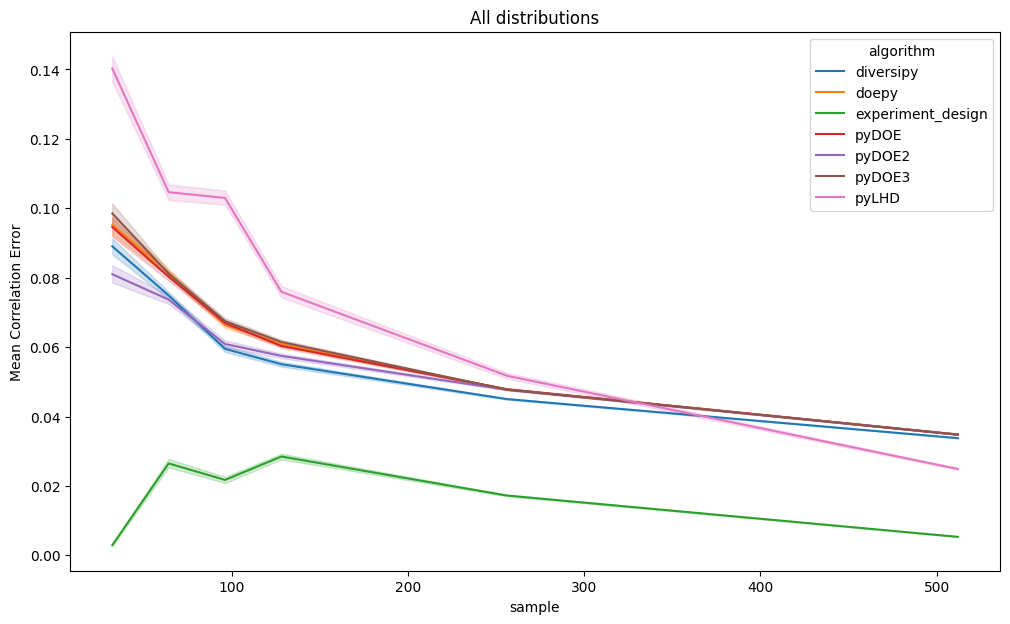
Even when restricting the analysis to uniform distributions as given below, experiment-design consistently achieves
lower correlation error, particularly in lower-dimensional settings.


Pairwise distance
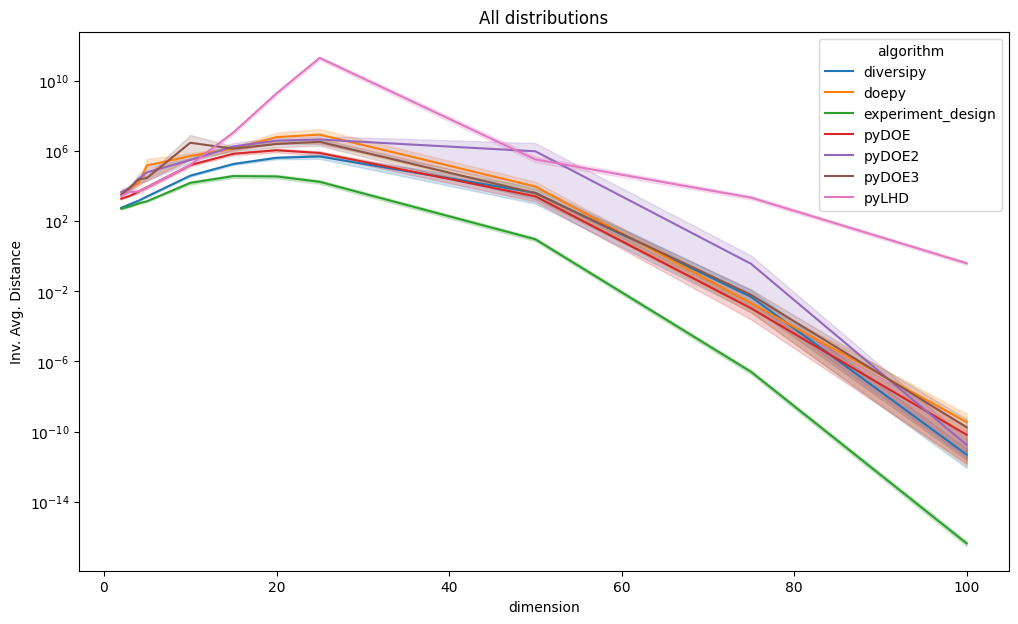
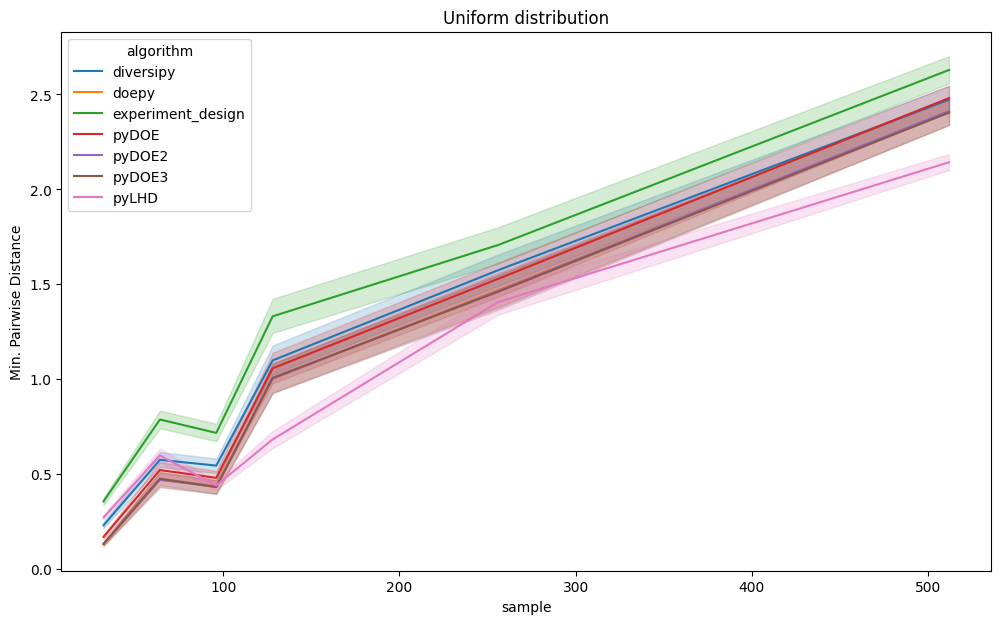
These metrics assess the space-filling properties of the DoE .
Higher minimum pairwise distance is better.
Lower inverse average distance is better.
Again, lines represent the average values of the metrics, whereas the areas represent the 95% confidence intervals.



Even when considering only uniform distributions as given below, experiment-design maintains a significant advantage.



Tested libraries
A non-exhaustive list of further LHS libraries available in python is given in this repository, which inspired this benchmark.
pyDOE, pyDOE2, pyDOE3: These libraries are among the first search results when looking for DoE tools, as the original pyDOE is one of the oldest Python libraries supporting DoE generation. They primarily focus on factorial designs and their derivatives but also include LHS functionality.
pyDOE2 is a direct fork of pyDOE, fixing some bugs and introducing generalized subset design. However, no changes were made to the LHS code.
These libraries support two LHS objectives:
maximinwhich maximizes the minimum distance andcorrelationwhich minimizes the maximum correlation coefficient. Since a choice is required when using thelhsfunction, pyDOE was tested withmaximin, while pyDOE2 was tested withcorrelation.pyDOE3 introduces an additional LHS objective,
lhsmu, which was used in this benchmark. See the linked documentation for further details.
doepy: This library looked promising, especially with a function called
space_filling_lhs. However, using this function currently results in an unresolved reference error. Therefore, the standardlhsfunction was used instead.doepy appears to be the only library natively supporting orthogonal sampling (i.e., DoE with non-uniform marginal distributions). However, passing distributions to its function does not seem to have any effect.
As a result, only uniform DoE were generated and mapped to non-uniform distributions via inverse transform sampling, just as with the other libraries.
If these issues are resolved in future updates, the benchmark results can be recomputed.
diversipy: This library is particularly useful due to its extensive DoE evaluation metrics in the indicator module. One of these,`average_inverse_dist <https://diversipy.readthedocs.io/en/latest/indicator.html>`_, was compelling enough to be included as an additional benchmark metric.
The function
cube.improved_latin_designwas used to generate LHS samples.
pyLHD: As one of the older DoE libraries, pyLHD implements various LHS methods. However, most of them impose constraints on the number of dimensions and samples.
The
maximinLHDfunction was used in this benchmark, as it provided the most flexibility in terms of sample size.The ability to generate flexible sample sizes is particularly important in modern computing, as it allows for efficient parallelization across arbitrary numbers of CPU cores or worker nodes.
Methods and metrics
For each algorithm, 64 DoE were generated for every combination of dimension, sample size, and distribution. Four probability distributions from the scipy.stats module were tested:
stats.uniform(loc=0, scale=1), # Uniform distribution [0, 1]
stats.norm(loc=0.5, scale=1 / 6.180464612335626), # Normal distribution ~ [0, 1] (95% of values)
stats.lognorm(0.448605225, scale=0.25), # Log-normal distribution ~ [0, 1] (95% of values)
stats.gumbel_r(loc=-2.81, scale=1.13), # Gumbel distribution ~ [-5, 5] (95% of values)
The table below shows the number of dimensions and corresponding sample sizes used for each distribution:
Dimensions |
Samples |
|---|---|
2, 3, 4, 5 |
32, 64, 96, 128 |
10, 15, 20, 25 |
64, 96, 128, 256 |
50, 75, 100 |
128, 256, 512 |
In total, 41 different (dimension, sample size) combinations were tested, across 4 distributions and 64 trials each, yielding \(41 \times 4 \times 64 = 10,496\) results per algorithm. Powers of two were chosen for sample sizes to align with common parallel computing setups, where computations are distributed across a power-of-two number of CPU cores or worker nodes.
Evaluation metrics
The following metrics were used:
Correlation Error
Maximum and mean correlation error (lower values are better).
Only non-correlated variables were considered to ensure fair comparisons.
Space-Filling Properties
Minimum pairwise distance (higher is better).
Inverse average distance (lower is better).
For libraries lacking native support for non-uniform distributions, uniform DoE were generated first and then transformed using inverse transform sampling.
Conclusion
experiment-design consistently produces the highest-quality LHS and orthogonal sampling designs.
This benchmark demonstrates that even the closest competing library performs significantly worse in at least 95% of tested
cases. The full benchmark code is available in the benchmark-2025-02 branch,
and all generated DoE can be found here
Beyond benchmark results, there are additional reasons to prefer experiment-design over the listed libraries.
As of this writing, none of these libraries natively support:
Correlated variables,
Non-uniform distributions,
Extending LHS by adding new samples while preserving LHS properties.